
 400-123-4567
400-123-4567
南卡大学的最新研究结果使AI可以“看到” AI
发布时间:2025-08-14 10:08
 8月8日,Openai发布了新一代人工智能GPT-5模型,该模型再次引起了全球关注。 Like large AIGC models such as Deepseek, Chatgpt, Thyi Qianwen, and Dubao gradually became a necessary "productivity tool" in education and work, their accompanying problems become more prominent: AI often "seriously talking nonsense", forming a reasonable information, " relying on AI tools to write homework and even graduation thesis, greatly affect academic and custom's integrity; The AI rate detection system needs to be improved, and the problem of false论文的错误经常发生...如何准确确定AI产生的内容已成为一个需要轻松解决的热门问题。
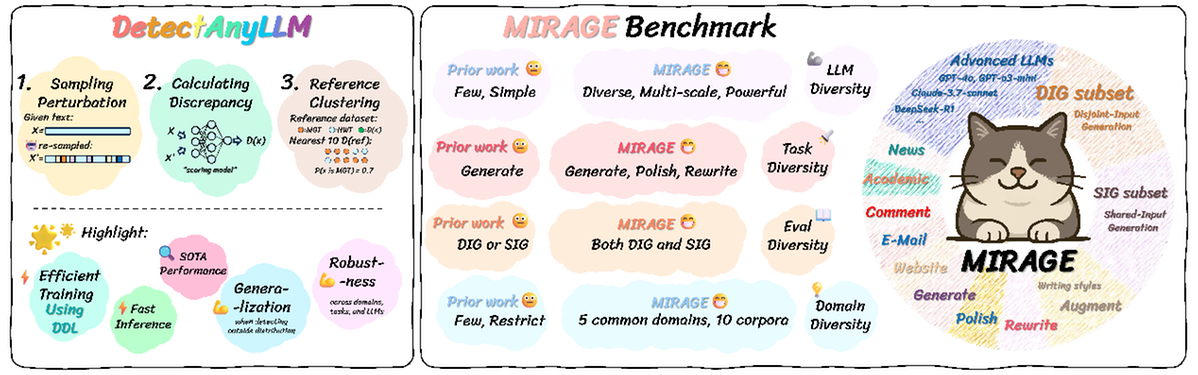
La显示了Rawan Dincectanyllm Discovery的轮廓以及Nankai University Research Team建议的Mirage基准数据集的亮点。
最近,南克计算机科学技术学院的媒体计算实验室AI大学取得了最新的研究结果。它不仅从审查的前景中揭示了现有的AI检测方法的性能,而且创新提出了“直接差异不同的研究”(DDL)的优化方法,这教会AI教AI使用“ Fire Eyes”来识别其他机器之间的差异并在AI绩效中实现重大崩溃。这些论文的相关论文被ACM MM 2025(ACM国际多媒体会议)接受,该论文是计算机多媒体领域领先的国际会议。
目前,有两条用于检测AI生成内容的主要路线。一种是“基于培训的发现方法”,该方法使用特定数据来培训专用的分类模型;另一个是“零样本检测方法”,该方法直接使用实践前语言模型,并指定了特定的分类标准进行分类。
许多研究表明,现有的发现方法通常在处理复杂的现实生活中表现不足。以前,强大的媒体报道说,经典作品,例如“莲花池中的月光”和“徘徊地球”,这是经常使用的AI发现AI速率系统注意到的。
为什么现有的AI检测工具“误解”?本文的第一本作者富·吉安(Fu Jiachen),也是2023年的2023年计算机科学卓越课程的本科生。
“从理论上讲,为了实现一般发现,有必要从所有大型培训模型中收集数据,但是当更改大型模型的情况下,现在几乎不可能。”福·吉安(Fu Jiachen)说,让探测器真正学习一个例子并改善检测器概括的性能是改善AI文本检测性能的关键。
到那时,研究团队提出了一种不同的方法来帮助模型知道AI文本检测的内在信息,直接优化模型条件条件的文本概率的可能性与由人为设置设置的目标值之间的差距。知识可以准确地获得人机文本之间的深层语义变化,从而大大提高了一般的一般能力和探测器的稳定性。
富·吉安(Fu Jiachen)说:“使用DDL训练的探测器就像拥有'Fire'Eyes'。尽管他们“只学会了” DeepSeek-R1文本,但他们可以准确地识别出最新的大型型号(例如GPT-5)产生的内容。”
该团队还提出了Mirage测试的全面测试基准,该测试使用了13个主流商业大型型号(例如Dubao,DeepSeek,Kimi等)和4个高级Mamale模型的开放资源(例如Qwen等),从三种观点中构建近100,000对人类文本:AI的产生,抛光和写作。
图显示了AI生成内容的发现的示意图
“ Mirage目前是专门针对发现商业大语模型的唯一一组基准数据。从直觉上讲,先前的基准数据已经从具有小而简单的功能的大型模型中积累了,而Mirage是17个具有强大功能的大型模型的共同建议,形成了一系列困难和代表性的论文。”朱·春(Guo Chunle)是南凯大学计算机科学学院的论文和副教授的相应集。
Mirage的测试结果表明,现有检测器的准确性已从90%的SA简单数据设置下降到约60%。虽然接受DDL训练的探测器仍然保持超过85%的精度。与斯坦福大学提出的检测相比表现有所提高71.62%;与马里兰大学,卡内基·梅隆大学等提出的双筒望远镜方法相比,表现的提高了68.03%。
“ AIGC每天都会发展。我们将继续重复和升级基准和考试技术,并尝试实现AI生成的文本的更快,更准确,更低的成本发现,并使用AI的功率使每个结果更加残留。” Li Chongyi,研究团队负责人,南卡大学计算机科学学院教授。
值得一提的是,第一张纸的富王是南凯大学的大二学生。上学后,在“第二次选择”之后,他被录取了大学科学科学科学课程,并进入了媒体计算实验室,以在两位导师李·宗教和郭·春儿的指导下开始一项科学实习研究。这也是一个南卡大学人才领先的创新培训改革的缩影 - “特殊班级”系列。
说到未来的研究计划,Fu Jichen将继续在生成人工智能领域进行探索。 “与我的新生一起参加科学研究是我的运气。教师和同学成功解决了实践问题。它不仅教会了我发表论文,而且还学会了发表福利纸工作。”
WS689C7290A3104BA1353FCAC7
https://tj.chinadaily.com.cn/a/a/202508/13/ws689c7290a3104ba135353fcac7.html
版权保护:本网站上发布的内容(包括文本,照片和多个媒体信息等。版权属于中国每日网络(Zhongbao International Cultural Media(Beijing)Co,Ltd。)。没有中国[email protected]
8月8日,Openai发布了新一代人工智能GPT-5模型,该模型再次引起了全球关注。 Like large AIGC models such as Deepseek, Chatgpt, Thyi Qianwen, and Dubao gradually became a necessary "productivity tool" in education and work, their accompanying problems become more prominent: AI often "seriously talking nonsense", forming a reasonable information, " relying on AI tools to write homework and even graduation thesis, greatly affect academic and custom's integrity; The AI rate detection system needs to be improved, and the problem of false论文的错误经常发生...如何准确确定AI产生的内容已成为一个需要轻松解决的热门问题。
La显示了Rawan Dincectanyllm Discovery的轮廓以及Nankai University Research Team建议的Mirage基准数据集的亮点。
最近,南克计算机科学技术学院的媒体计算实验室AI大学取得了最新的研究结果。它不仅从审查的前景中揭示了现有的AI检测方法的性能,而且创新提出了“直接差异不同的研究”(DDL)的优化方法,这教会AI教AI使用“ Fire Eyes”来识别其他机器之间的差异并在AI绩效中实现重大崩溃。这些论文的相关论文被ACM MM 2025(ACM国际多媒体会议)接受,该论文是计算机多媒体领域领先的国际会议。
目前,有两条用于检测AI生成内容的主要路线。一种是“基于培训的发现方法”,该方法使用特定数据来培训专用的分类模型;另一个是“零样本检测方法”,该方法直接使用实践前语言模型,并指定了特定的分类标准进行分类。
许多研究表明,现有的发现方法通常在处理复杂的现实生活中表现不足。以前,强大的媒体报道说,经典作品,例如“莲花池中的月光”和“徘徊地球”,这是经常使用的AI发现AI速率系统注意到的。
为什么现有的AI检测工具“误解”?本文的第一本作者富·吉安(Fu Jiachen),也是2023年的2023年计算机科学卓越课程的本科生。
“从理论上讲,为了实现一般发现,有必要从所有大型培训模型中收集数据,但是当更改大型模型的情况下,现在几乎不可能。”福·吉安(Fu Jiachen)说,让探测器真正学习一个例子并改善检测器概括的性能是改善AI文本检测性能的关键。
到那时,研究团队提出了一种不同的方法来帮助模型知道AI文本检测的内在信息,直接优化模型条件条件的文本概率的可能性与由人为设置设置的目标值之间的差距。知识可以准确地获得人机文本之间的深层语义变化,从而大大提高了一般的一般能力和探测器的稳定性。
富·吉安(Fu Jiachen)说:“使用DDL训练的探测器就像拥有'Fire'Eyes'。尽管他们“只学会了” DeepSeek-R1文本,但他们可以准确地识别出最新的大型型号(例如GPT-5)产生的内容。”
该团队还提出了Mirage测试的全面测试基准,该测试使用了13个主流商业大型型号(例如Dubao,DeepSeek,Kimi等)和4个高级Mamale模型的开放资源(例如Qwen等),从三种观点中构建近100,000对人类文本:AI的产生,抛光和写作。
图显示了AI生成内容的发现的示意图
“ Mirage目前是专门针对发现商业大语模型的唯一一组基准数据。从直觉上讲,先前的基准数据已经从具有小而简单的功能的大型模型中积累了,而Mirage是17个具有强大功能的大型模型的共同建议,形成了一系列困难和代表性的论文。”朱·春(Guo Chunle)是南凯大学计算机科学学院的论文和副教授的相应集。
Mirage的测试结果表明,现有检测器的准确性已从90%的SA简单数据设置下降到约60%。虽然接受DDL训练的探测器仍然保持超过85%的精度。与斯坦福大学提出的检测相比表现有所提高71.62%;与马里兰大学,卡内基·梅隆大学等提出的双筒望远镜方法相比,表现的提高了68.03%。
“ AIGC每天都会发展。我们将继续重复和升级基准和考试技术,并尝试实现AI生成的文本的更快,更准确,更低的成本发现,并使用AI的功率使每个结果更加残留。” Li Chongyi,研究团队负责人,南卡大学计算机科学学院教授。
值得一提的是,第一张纸的富王是南凯大学的大二学生。上学后,在“第二次选择”之后,他被录取了大学科学科学科学课程,并进入了媒体计算实验室,以在两位导师李·宗教和郭·春儿的指导下开始一项科学实习研究。这也是一个南卡大学人才领先的创新培训改革的缩影 - “特殊班级”系列。
说到未来的研究计划,Fu Jichen将继续在生成人工智能领域进行探索。 “与我的新生一起参加科学研究是我的运气。教师和同学成功解决了实践问题。它不仅教会了我发表论文,而且还学会了发表福利纸工作。”
WS689C7290A3104BA1353FCAC7
https://tj.chinadaily.com.cn/a/a/202508/13/ws689c7290a3104ba135353fcac7.html
版权保护:本网站上发布的内容(包括文本,照片和多个媒体信息等。版权属于中国每日网络(Zhongbao International Cultural Media(Beijing)Co,Ltd。)。没有中国[email protected] 下一篇:day -day